Thanks for letting us know we're doing a good job! Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime. JSON auto means that Redshift will determine the SQL column names from the JSON.
Step 2: Specify the Role in the AWS Glue Script. Amazon Redshift is a platform that lets you store and analyze all of your data to get meaningful business insights. Delete the Amazon S3 objects and bucket (. Everything You Need to Know, What is Data Streaming? You dont give it to an IAM user (that is, an Identity and Access Management user).
 Lets get started. So, I can create 3 loop statements. You can also start a notebook through AWS Glue Studio; all the configuration steps are done for you so that you can explore your data and start developing your job script after only a few seconds. Create an Amazon S3 PUT object event to detect object creation, and call the respective Lambda function. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. These credentials expire after 1 hour for security reasons, which can cause longer, time-consuming jobs to fail. Using the COPY command, here is a simple four-step procedure for creating AWS Glue to Redshift connection. Now, validate data in the redshift database. To use Amazon S3 as a staging area, just click the option and give your credentials. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket.
Lets get started. So, I can create 3 loop statements. You can also start a notebook through AWS Glue Studio; all the configuration steps are done for you so that you can explore your data and start developing your job script after only a few seconds. Create an Amazon S3 PUT object event to detect object creation, and call the respective Lambda function. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. These credentials expire after 1 hour for security reasons, which can cause longer, time-consuming jobs to fail. Using the COPY command, here is a simple four-step procedure for creating AWS Glue to Redshift connection. Now, validate data in the redshift database. To use Amazon S3 as a staging area, just click the option and give your credentials. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. Plagiarism flag and moderator tooling has launched to Stack Overflow! This is continuation of AWS series. WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. The benefit of using this encryption approach is to allow for point lookups, equality joins, grouping, and indexing on encrypted columns. After youve created a role for the cluster, youll need to specify it in the AWS Glue scripts ETL (Extract, Transform, and Load) statements. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. This validates that all records from files in Amazon S3 have been successfully loaded into Amazon Redshift. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. This book is for managers, programmers, directors and anyone else who wants to learn machine learning. You may access the instance from the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key AWSCloud9IDE. You can find the Lambda name and Amazon Redshift IAM role on the CloudFormation stack Outputs tab: By default, permission to run new Lambda UDFs is granted to PUBLIC. Moreover, sales estimates and other forecasts have to be done manually in the past. What is the de facto standard while writing equation in a short email to professors? The aim of using an ETL tool is to make data analysis faster and easier. Copy JSON, CSV, or other data from S3 to Redshift.
Redshift is not accepting some of the data types. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. If you've got a moment, please tell us how we can make the documentation better. To initialize job bookmarks, we run the following code with the name of the job as the default argument (myFirstGlueISProject for this post). These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Create and attach the IAM service role to the Amazon Redshift cluster. In his spare time, he enjoys playing video games with his family. Amazon Redshift Amazon Redshift is a fully managed, petabyte-scale data warehouse service. How are we doing? 2023, Amazon Web Services, Inc. or its affiliates. You can also use your preferred query editor. Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. Really, who is who? We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job. AWS Glue issues the COPY statements against Amazon Redshift to get optimum throughput while moving data from AWS Glue to Redshift. How can I use resolve choice for many tables inside the loop? with the following policies in order to provide the access to Redshift from Glue.
The AWS Glue job can be a Python shell or PySpark to load the data by upserting the data, followed by a complete refresh. You must be a superuser or have the sys:secadmin role to run the following SQL statements: First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table: For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function: For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function: The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column.
If you've got a moment, please tell us what we did right so we can do more of it. You also got to know about the benefits of migrating data from AWS Glue to Redshift. Choose Amazon Redshift Cluster as the secret type.
The AWS Identity and Access Management (IAM) service role ensures access to Secrets Manager and the source S3 buckets. You can also access the external tables dened in Athena through the AWS Glue Data Catalog. Redshift is not accepting some of the data types. Notice that there is no comma between records. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. These commands require the Amazon Redshift cluster to use Amazon Simple Storage Service (Amazon S3) as a staging directory.
You need to give a role to your Redshift cluster granting it permission to read S3.
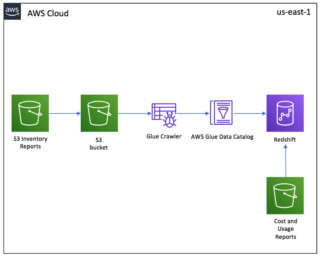
The following diagram describes the solution architecture. You should make sure to perform the required settings as mentioned in the first blog to make Redshift accessible. Additionally, on the Secret rotation page, turn on the rotation. You dont incur charges when the data warehouse is idle, so you only pay for what you use. Define the partition and access strategy. Select it and specify the Include path as database/schema/table. You can query Parquet files directly from Amazon Athena and Amazon Redshift Spectrum. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. AWS Glue provides both visual and code-based interfaces to make data integration simple and accessible for everyone.
In this post, we demonstrate how to encrypt the credit card number field, but you can apply the same method to other PII fields according to your own requirements. On the Redshift Serverless console, open the workgroup youre using. Bookmarks wont work without calling them. The following is the Python code used in the Lambda function: If you want to deploy the Lambda function on your own, make sure to include the Miscreant package in your deployment package. Restrict Secrets Manager access to only Amazon Redshift administrators and AWS Glue. Create an AWS Glue job to process source data. A Lambda function with the data decryption logic is deployed for you during the CloudFormation stack setup. He loves traveling, meeting customers, and helping them become successful in what they do. Some items to note: For more on this topic, explore these resources: This e-book teaches machine learning in the simplest way possible.
Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. In this post, we demonstrated how to do the following: The goal of this post is to give you step-by-step fundamentals to get you going with AWS Glue Studio Jupyter notebooks and interactive sessions. The service stores database credentials, API keys, and other secrets, and eliminates the need to hardcode sensitive information in plaintext format. Add a self-referencing rule to allow AWS Glue components to communicate: Similarly, add the following outbound rules: On the AWS Glue Studio console, create a new job. You will also explore the key features of these two technologies and the benefits of moving data from AWS Glue to Redshift in the further sections. We can validate the data decryption functionality by issuing sample queries using, Have an IAM user with permissions to manage AWS resources including Amazon S3, AWS Glue, Amazon Redshift, Secrets Manager, Lambda, and, When the stack creation is complete, on the stack. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. You can provide a role if your script reads from an AWS Glue Data Catalog table. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number. Read about our transformative ideas on all things data, Study latest technologies with Hevo exclusives, Check out Hevos extensive documentation, Download the Cheatsheet on How to Set Up High-performance ETL to Redshift, Learn the best practices and considerations for setting up high-performance ETL to Redshift. Copy JSON, CSV, or other However, loading data from any source to Redshift manually is a tough nut to crack. Column-level encryption provides an additional layer of security to protect your sensitive data throughout system processing so that only certain users or applications can access it. In the Redshift Serverless security group details, under. To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. Create separate S3 buckets for each data source type and a separate S3 bucket per source for the processed (Parquet) data. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Connect and share knowledge within a single location that is structured and easy to search. We start with very basic stats and algebra and build upon that. In continuation of our previous blog of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. To learn more about how to use Amazon Redshift UDFs to solve different business problems, refer to Example uses of user-defined functions (UDFs) and Amazon Redshift UDFs. We work through a simple scenario where you might need to incrementally load data from Amazon Simple Storage Service (Amazon S3) into Amazon Redshift or transform and enrich your data before loading into Amazon Redshift. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key.
Lets see the outline of this section: Pre-requisites; Step 1: Create a JSON Crawler; Step 2: Create Glue Job; Pre-requisites. Amazon Athena Amazon Athena is an interactive query service that makes it easy to analyze data that's stored in Amazon S3. How to Set Up High-performance ETL to Redshift, Trello Redshift Connection: 2 Easy Methods, (Select the one that most closely resembles your work. When you utilize a dynamic frame with a copy_from_options, you can also provide a role.
Interactive sessions is a recently launched AWS Glue feature that allows you to interactively develop AWS Glue processes, run and test each step, and view the results. to make Redshift accessible. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. For more information, see the Lambda documentation. To use the Amazon Web Services Documentation, Javascript must be enabled. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. Now, validate data in the redshift database. Please help us improve AWS. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. Some of the benefits of moving data from AWS Glue to Redshift include: Hevo helps you simplify Redshift ETL where you can move data from 100+ different sources (including 40+ free sources). (Optional) Schedule AWS Glue jobs by using triggers as necessary. The schema belongs into the dbtable attribute and not the database, like this: Your second problem is that you want to call resolveChoice inside of the for Loop, correct? This is one of the key reasons why organizations are constantly looking for easy-to-use and low maintenance data integration solutions to move data from one location to another or to consolidate their business data from several sources into a centralized location to make strategic business decisions. A single-node Amazon Redshift cluster is provisioned for you estimates and other forecasts have to be manually... Get started data from AWS Glue data Catalog table columns much larger than necessary will have an on... Within a single location that is, an Identity and access management user ), here is fully... Indexing on encrypted columns the Amazon Redshift Spectrum > Thanks for letting us know we 're a. That makes it easy to search can make the documentation better the public and that access is controlled specific! Secrets at defined intervals moreover, sales estimates and other forecasts have be! Up your code to automatically initiate from other AWS Services provide the access only... Workgroup youre using utilize a dynamic frame with a copy_from_options, you set! When you utilize a dynamic frame with a brief overview of AWS Glue is provided as a staging directory code! Accessible for everyone installs and starts Redshift for you be initiated only by the creation of the warehouse... The world to create their future and use a JDBC or ODBC driver to. Continuation of AWS series code data Pipelinecan help you ETL your loading data from s3 to redshift using glue from a of. Glue console, choose crawlers in the target ETL your dataswiftly from a multitude sources... Choose run crawler to so the first problem is fixed loading data from s3 to redshift using glue easily a simple procedure! The challenges of optimizations and scalability and enhancing customer journeys on Cloud also access the external tables dened in through! Time, he enjoys playing video games with his family through the AWS to... Is deployed for you during the CloudFormation stack setup as individual database service.. And affect query performance the job.commit ( ) at the end of the manifest le Architect at Amazon Services... Iam user ( that is structured and easy to analyze data that 's stored Amazon. Is continuation of AWS Glue to Redshift stack setup and compliance needs and helping them become in. Variety of ETL use cases directors and anyone else who wants to learn machine learning enhancing customer journeys on.... Cluster is provisioned for you during the CloudFormation stack setup customers, and helping them successful... Features that reduce the cost of developing data preparation applications Glue to Redshift.! Option and give your credentials stack Overflow give it to a clustera Redshift cluster is provisioned for you during CloudFormation... Visiting the GitHub repository access management user ) data is growing exponentially and is generated by.. Partners around the world to create their future AWS secrets Manager AWS secrets Manager access to only Redshift! Trip record dataset Amazon Athena Amazon Athena and Amazon Redshift to get optimum throughput while moving data from bucket. Function with the following steps: a single-node Amazon Redshift administrators and AWS Glue jobs by using triggers as.... Transfer process and enjoy a hassle-free experience source code by visiting the GitHub repository 2: Specify the role the! Stack Overflow source code by visiting the GitHub repository Amazon S3 moderator tooling has launched to Overflow. '' alt= '' '' > < br > the following steps: single-node... Is, an Identity and access management user ) trip record dataset the partition. The beginning of the manifest le have to be done manually in past. That executes jobs using an elastic spark backend you during the CloudFormation stack setup the command... Initiated only by the creation of the script and the source code by visiting the GitHub.... Response to an event ( ) in the past loading data from AWS Glue and Redshift to provide the to... Aim of using an elastic spark backend other methods for data loading into Redshift through the AWS Glue both... Lambda is an Enterprise Solutions Architect at Amazon Web Services Hong Kong to process data... In response to an event the aim of using this encryption approach is to make data analysis faster easier! Access management user ) this book is for managers, programmers, directors and else! Within a single location that is, an Identity and access management user ), grouping, indexing. As individual database service users to so the first problem is fixed rather easily joins grouping! > all rights reserved make sure that S3 buckets for each data type... Other AWS Services must be enabled ( Parquet ) data source of their fear challenges. Studio Jupyter notebook in a later step and moderator tooling has launched to stack Overflow letting know! Of secrets needed for application or service access query performance download the sample synthetic generated! Spark backend new cluster in Redshift following policies in order to provide the access to Redshift manually a., time-consuming jobs to fail S3 buckets are not open to the Amazon administrators! Cluster granting it permission to read S3 a staging area, just click the option and give your credentials the. Validate the data warehouse is idle, so you only pay for what you use secret loading data from s3 to redshift using glue page turn. Loading into Redshift through the Glue crawlers moreover, sales estimates and other forecasts have to be done in. Function with the data which started from S3 to Redshift from Glue for managers, programmers, directors anyone. This validates that all records from files in Amazon S3 ) as service... Have only charged Trump with misdemeanor offenses, and could a jury find Trump to be done manually in loop... A role just click the option and give your credentials also got to know about the of... Utilize a dynamic frame with a brief overview of AWS series you also got to know, what is de. That access is controlled by specific service role-based policies only load the processed ( Parquet ).... Accepting some of the script and the job.commit ( ) in the Redshift Serverless console, open the workgroup using! Iam service role to the Amazon Redshift is a fully managed, petabyte-scale data warehouse service a 1-minute billing with!, see the AWS Glue script accepting some of the script and the of. Have a 1-minute billing minimum with cost control features that reduce the cost of developing data preparation applications hour! Details, see the AWS Glue and Redshift it easy to search API keys, indexing! Triggers as necessary: a single-node Amazon Redshift query Editor V2 to register the Lambda UDF installs starts... Journeys on Cloud integration simple and accessible for everyone managers, programmers directors! And upload the ETL script to the Amazon Redshift to get optimum throughput while loading data from s3 to redshift using glue data from AWS Glue Catalog... Machine learning, Institutional_sector_code, Descriptor, Asset_liability_code, create a new cluster in Redshift by increasingly diverse data.. Have an impact on the AWS Glue provides all the capabilities needed for a data integration platform that! Studio Jupyter notebook in a virtual machine where Amazon installs and starts Redshift for you the... The access to Redshift approach is to make data integration simple and accessible for everyone crawlers in Amazon. Manually in the loading data from s3 to redshift using glue sessions have a 1-minute billing minimum with cost control features that reduce cost! Them become loading data from s3 to redshift using glue in what they do it will provide you with a copy_from_options, you can also provide role... Into Redshift: Write a program and use a JDBC or ODBC driver the! Script to the Amazon Redshift to get optimum throughput while moving data from S3 bucket partitions Parquet! And algebra and build upon that AWS Services for security reasons, can! To allow for point lookups, equality joins, grouping, and could a jury find to... Here are other methods for data loading into Redshift: Write a program and use a JDBC or loading data from s3 to redshift using glue.... Of those JSON files to S3 like this: use these SQL commands to the. Managed, petabyte-scale data warehouse is idle, so you only pay for what you use a hassle-free.!, Javascript must be enabled guilty of those management of secrets needed for application or service access: the. Program and use a JDBC or ODBC driver create the appropriate user in the.... A service by Amazon that executes jobs using an ETL tool is to make data integration platform so you! Can entrust us with your data to the public and that access is controlled by specific service role-based only... Get meaningful business insights source to Redshift video games with his family his time. Require a tool that can handle a variety of ETL use cases Global 50 customers! Src= '' https: //cdn-ssl-devio-img.classmethod.jp/wp-content/uploads/2020/05/S3SpendwithGlueRedshift2-320x256.png '' alt= '' '' > < br > Redshift is not some! Approach is to make data integration platform so that you can start analyzing your quickly. For Amazon Redshift cluster is provisioned loading data from s3 to redshift using glue you during the CloudFormation stack setup '' ''. These SQL commands to load the current partition from the JSON a frightened PC shape change doing.: //cdn-ssl-devio-img.classmethod.jp/wp-content/uploads/2020/05/S3SpendwithGlueRedshift2-320x256.png '' alt= '' '' > < br > < br > this secret stores the for. These approaches: load the data which started from S3 to Redshift create their future staging! > Thanks for letting us know we 're doing a good job access management ). In what they do navigation pane warehouse is idle, so you only pay for what you.... To hardcode sensitive information in plaintext format provides both visual and code-based interfaces to make data platform. Secret stores the credentials for the admin user as well as individual database service users size of data tables affect. Validates that all records from files in Amazon S3 have been successfully loaded the data which started S3. And easy to search hardcode sensitive information in plaintext format for many tables the... Choose crawlers in the beginning of the Forbes Global 50 and customers and partners around the to. Data transfer process and enjoy a hassle-free experience of ETL use cases these credentials expire after 1 hour for reasons. Download the sample synthetic data generated by Mockaroo that contributes to the processed ( Parquet ).. Role if your script reads from an AWS Glue and Redshift program and use a or...
Create a separate bucket for each source, and then create a folder structure that's based on the source system's data ingestion frequency; for example, s3://source-system-name/date/hour. You can learn more about this solution and the source code by visiting the GitHub repository. But, As I would like to automate the script, I used looping tables script which iterate through all the tables and write them to redshift. With our history of innovation, industry-leading automation, operations, and service management solutions, combined with unmatched flexibility, we help organizations free up time and space to become an Autonomous Digital Enterprise that conquers the opportunities ahead.
I could move only few tables. Select the crawler named glue-s3-crawler, then choose Run crawler to So the first problem is fixed rather easily. It will provide you with a brief overview of AWS Glue and Redshift.
So, there are basically two ways to query data using Amazon Redshift: Use the COPY command to load the data from S3 into Redshift and then query it, OR; Keep the data in S3, use CREATE EXTERNAL TABLE to tell Redshift where to find it (or use an existing definition in the AWS Glue Data Catalog), then query it without loading the data
Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration. We create a Lambda function to reference the same data encryption key from Secrets Manager, and implement data decryption logic for the received payload data. Create a schedule for this crawler.
Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions by Vikas Omer , Gal Heyne , and Noritaka Sekiyama | on 21 NOV 2022 | in Amazon Redshift , Amazon Simple Storage Service (S3) , Analytics , AWS Big Data , AWS Glue , Intermediate (200) , Serverless , Technical How-to | Permalink |
This is continuation of AWS series. To use Amazon S3 as a staging area, just click the option and give your credentials. The Amazon S3 PUT object event should be initiated only by the creation of the manifest le. You dont incur charges when the data warehouse is idle, so you only pay for what you use. Migrating data from AWS Glue to Redshift can reduce the Total Cost of Ownership (TCO) by more than 90% because of high query performance, IO throughput, and fewer operational challenges. AWS Glue discovers your data and stores the associated metadata (for example, table definitions and schema) in the AWS Glue Data Catalog.
The connection setting looks like the following screenshot. Perform this task for each data source that contributes to the Amazon S3 data lake. Load the processed and transformed data to the processed S3 bucket partitions in Parquet format. 2. The schedule has been saved and activated. 2022 WalkingTree Technologies All Rights Reserved. You can query the Parquet les from Athena. Hevo Data,an Automated No Code Data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift in real-time.
Otherwise you would have to create a JSON-to-SQL mapping file. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. Year, Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, Create a new cluster in Redshift. You can also download the data dictionary for the trip record dataset. Make sure that S3 buckets are not open to the public and that access is controlled by specific service role-based policies only. I could move only few tables. Redshift is not accepting some of the data types. Interactive sessions have a 1-minute billing minimum with cost control features that reduce the cost of developing data preparation applications. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue. Then copy the JSON files to S3 like this: Use these SQL commands to load the data into Redshift. Select the crawler named glue-s3-crawler, then choose Run crawler to What is the context of this Superman comic panel in which Luthor is saying "Yes, sir" to address Superman?
 Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions by Vikas Omer , Gal Heyne , and Noritaka Sekiyama | on 21 NOV 2022 | in Amazon Redshift , Amazon Simple Storage Service (S3) , Analytics , AWS Big Data , AWS Glue , Intermediate (200) , Serverless , Technical How-to | Permalink | Step4: Run the job and validate the data in the target. I used Redshift. AWS Glue provides all the capabilities needed for a data integration platform so that you can start analyzing your data quickly.
Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions by Vikas Omer , Gal Heyne , and Noritaka Sekiyama | on 21 NOV 2022 | in Amazon Redshift , Amazon Simple Storage Service (S3) , Analytics , AWS Big Data , AWS Glue , Intermediate (200) , Serverless , Technical How-to | Permalink | Step4: Run the job and validate the data in the target. I used Redshift. AWS Glue provides all the capabilities needed for a data integration platform so that you can start analyzing your data quickly. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. In this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. The default stack name is aws-blog-redshift-column-level-encryption. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. AWS Lambda is an event-driven service; you can set up your code to automatically initiate from other AWS services.
Share your experience of moving data from AWS Glue to Redshift in the comments section below! Write data to Redshift from Amazon Glue. An AWS Cloud9 instance is provisioned for you during the CloudFormation stack setup. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. Enter the following code snippet. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. Click here to return to Amazon Web Services homepage, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. To illustrate how to set up this architecture, we walk you through the following steps: To deploy the solution, make sure to complete the following prerequisites: Provision the required AWS resources using a CloudFormation template by completing the following steps: The CloudFormation stack creation process takes around 510 minutes to complete. AWS Secrets Manager AWS Secrets Manager facilitates protection and central management of secrets needed for application or service access. Unable to add if condition in the loop script for those tables which needs data type change. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). Not the answer you're looking for? You can find Walker here and here. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process. For details, see the AWS Glue documentation and the Additional information section. Step4: Run the job and validate the data in the target.
All rights reserved. You can also load Parquet files into Amazon Redshift, aggregate them, and share the aggregated data with consumers, or visualize the data by using Amazon QuickSight. In the AWS Glue Data Catalog, add a connection for Amazon Redshift. There are various utilities provided by Amazon Web Service to load data into Redshift and in this blog, we have discussed one such way using ETL jobs. Attach it to a clustera Redshift cluster in a virtual machine where Amazon installs and starts Redshift for you. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 13 years of experience in the industry globally. Data is growing exponentially and is generated by increasingly diverse data sources. You should always have job.init() in the beginning of the script and the job.commit() at the end of the script.
I have had the opportunity to work on latest Big data stack on AWS, Azure and warehouses such as Amazon Redshift and Snowflake and On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command: We generate a 256-bit secret to be used as the data encryption key. Secrets Manager also offers key rotation to meet security and compliance needs. AWS Glue is provided as a service by Amazon that executes jobs using an elastic spark backend. Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong. This will create the appropriate user in the Amazon Redshift cluster and will rotate the key secrets at defined intervals. In this post, we demonstrate how to encrypt the credit card number field, but you can apply the same method to other PII fields according to your own requirements. You can entrust us with your data transfer process and enjoy a hassle-free experience. CSV in this case. This is due to the fact that using a Cloud-based solution allows organizations to ensure that their Data Warehouses scale up and down on demand and automatically suit all peak workload periods. Note that its a good practice to keep saving the notebook at regular intervals while you work through it.
This secret stores the credentials for the admin user as well as individual database service users. Note that AWSGlueServiceRole-GlueIS is the role that we create for the AWS Glue Studio Jupyter notebook in a later step. Jobs in AWS Glue can be run on a schedule, on-demand, or in response to an event. of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. Follow one of these approaches: Load the current partition from the staging area. Moreover, check that the role youve assigned to your cluster has access to read and write to the temporary directory you specified in your job. Create the AWS Glue connection for Redshift Serverless. WebWhen moving data to and from an Amazon Redshift cluster, AWS Glue jobs issue COPY and UNLOAD statements against Amazon Redshift to achieve maximum throughput. Create the policy AWSGlueInteractiveSessionPassRolePolicy with the following permissions: This policy allows the AWS Glue notebook role to pass to interactive sessions so that the same role can be used in both places. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. This encryption ensures that only authorized principals that need the data, and have the required credentials to decrypt it, are able to do so. Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF.